每个外设都是通过读写其寄存器来控制的。外设寄存器也称为I/O端口,通常包括:控制寄存器、状态寄存器和数据寄存器三大类。根据访问外设寄存器的不同方式,可以把CPU分成两大类。一类CPU(如M68K,Power PC等)把这些寄存器看作内存的一部分,寄存器参与内存统一编址,访问寄存器就通过访问一般的内存指令进行,所以,这种CPU没有专门用于设备I/O的指令。这就是所谓的“I/O内存”方式。另一类CPU(典型的如X86),将外设的寄存器看成一个独立的地址空间,所以访问内存的指令不能用来访问这些寄存器,而要为对外设寄存器的读/写设置专用指令,如IN和OUT指令。这就是所谓的“ I/O端口”方式。但是,用于I/O指令的“地址空间”相对来说是很小的,如x86 CPU的I/O空间就只有64KB(0-0xffff)。
结合下图,我们彻底讲述IO端口和IO内存以及内存之间的关系。主存16M字节的SDRAM,外设是个视频采集卡,上面有16M字节的SDRAM作为缓冲区。

1. CPU是i386的情况
在i386系列的处理中,内存和外部IO是独立编址,也是独立寻址的。MEM的内存空间是32位可以寻址到4G,IO空间是16位可以寻址到64K。
在内核中,访问外设上的IO Port必须通过IO Port的寻址方式。而访问IO Mem就比较罗嗦,外部MEM不能和主存一样访问,虽然大小上不相上下,可是外部MEM是没有在系统中注册的。访问外部IO MEM必须通过remap映射到内核的MEM空间后才能访问。为了达到接口的同一性,内核提供了IO Port到IO Mem的映射函数。映射后IO Port就可以看作是IO Mem,按照IO Mem的访问方式即可。
3. CPU是ARM或PPC架构的情况
在这一类的处理器中,IO Port的寻址方式是采用内存映射,也就是IO bus就是Mem bus。系统的寻址能力如果是32位,IO Port+Mem(包括IO Mem)可以达到4G。
1.使用I/O 端口
I/O 端口是驱动用来和很多设备通讯的方法。
1.1、分配I/O 端口
在驱动还没独占设备之前,不应对端口进行操作。内核提供了一个注册接口,以允许驱动声明其需要的端口:
| #include <linux/ioport.h> /* request_region告诉内核:要使用first开始的n个端口。参数name为设备名。如果分配成功返回值是非NULL;否则无法使用需要的端 口(/proc/ioports包含了系统当前所有端口的分配信息,若request_region分配失败时,可以查看该文件,看谁先用了你要的端口) */ struct resource *request_region(unsigned long first, unsigned long n, const char *name); /* 用完I/O端口后(可能在模块卸载时),应当调用release_region将I/O端口返还给系统。参数start和n应与之前传递给request_region一致 */ void release_region(unsigned long start, unsigned long n); /* check_region用于检查一个给定的I/O端 口集是否可用。如果给定的端口不可用,check_region返回一个错误码。不推荐使用该函数,因为即便它返回0(端口可用),它也不能保证后面的端 口分配操作会成功,因为检查和后面的端口分配并不是一个原子操作。而request_region通过加锁来保证操作的原子性,因此是安全的 */ int check_region(unsigned long first, unsigned long n); |
1.2、操作I/O端口
在驱动成功请求到I/O 端口后,就可以读写这些端口了。大部分硬件会将8位、16位和32位端口区分开,无法像访问内存那样混淆使用。驱动程序必须调用不同的函数来访问不同大小的端口。
如同前面所讲的,仅支持单地址空间的计算机体系通过将I/O端口地址重新映射到内存地址来伪装端口I/O 。为了提高移植性,内核对驱动隐藏了这些细节。Linux 内核头文件(体系依赖的头文件<asm/io.h>) 定义了下列内联函数来存取I/O端口:
| /* inb/outb:读/写字节端口(8位宽)。有些体系将port参数定义为unsigned long;而有些平台则将它定义为unsigned short。inb的返回类型也是依赖体系的 */ unsigned inb(unsigned port); void outb(unsigned char byte, unsigned port); /* inw/outw:读/写字端口(16位宽) */ unsigned inw(unsigned port); void outw(unsigned short word, unsigned port); /* inl/outl:读/写32位端口。longword也是依赖体系的,有的体系为unsigned long;而有的为unsigned int */ unsigned inl(unsigned port); void outl(unsigned longword, unsigned port); |
从现在开始,当我们使用unsigned 没有进一步指定类型时,表示是一个依赖体系的定义。
注意,没有64位的I/O端口操作函数。即便在64位体系中,端口地址空间使用一个32位(最大)的数据通路。
1.3、从用户空间访问I/O端口
1.2节介绍的函数主要是提供给驱动使用,但它们也可在用户空间使用,至少在PC机上可以。GNU C 库在 <sys/io.h> 中定义它们。如果在用户空间使用这些函数,必须满足下列条件:
1)、程序必须使用-O选项编译来强制扩展内联函数
2)、必须使用ioperm和iopl系统调用(#include <sys/perm.h>) 来获得进行操作I/O端口的权限。ioperm 为获取单个端口的操作许可,iopl 为获取整个I/O空间许可。这2个函数都是x86特有的
3)、程序必须以root来调用ioperm或者iopl,或者其父进程(祖先)必须以root获得的端口操作权限
如果平台不支持ioperm和iopl系统调用,通过使用/dev/prot设备文件,用户空间仍然可以存取I/O 端口。但是要注意的是,这个文件的定义也是依赖平台的。
1.4、字串操作
除了一次传递一个数据的I/O操作,某些处理器实现了一次传递一序列数据(单位可以是字节、字和双字)的特殊指令。这些所谓的字串指令,它们完成任务比一个C语言循环更快。下列宏定义实现字串操作,在某些体系上,它们通过使用单个机器指令实现;但如果目标处理器没有进行字串I/O指令,则通过执行一个紧凑的循环实现。
字串函数的原型是:
| /* insb:从I/O端口port读取count个数据(单位字节)到以内存地址addr为开始的内存空间 */ void insb(unsigned port, void *addr, unsigned long count); /* outsb:将内存地址addr开始的count个数据(单位字节)写到I/O端口port */ void outsb(unsigned port, void *addr, unsigned long count); /* insw:从I/O端口port读取count个数据(单位字)到以内存地址addr为开始的内存空间 */ void insw(unsigned port, void *addr, unsigned long count); /* outsw:将内存地址addr开始的count个数据(单位字)写到I/O端口port */ void outsw(unsigned port, void *addr, unsigned long count); /* insl:从I/O端口port读取count个数据(单位双字)到以内存地址addr为开始的内存空间 */ void insl(unsigned port, void *addr, unsigned long count); /* outsl:将内存地址addr开始的count个数据(单位双字)写到I/O端口port */ void outsl(unsigned port, void *addr, unsigned long count); |
注意:使用字串函数时,它们直接将字节流从端口中读取或写入。当端口和主机系统有不同的字节序时,会导致不可预期的结果。使用 inw读取端口应在必要时自行转换字节序,以匹配主机字节序。
1.5、暂停式I/O操作函数
由于处理器的速率可能与外设(尤其是低速设备)的并不匹配,当处理器过快地传送数据到或自总线时,这时可能就会引起问题。解决方法是:如果在I/O 指令后面紧跟着另一个相似的I/O 指令,就必须插入一个小的延时。为此,Linux提供了暂停式I/O操作函数,这些函数的名子只是在非暂停式I/O操作函数(前面提到的那些I/O操作函数都是非暂停式的)名后加上_p ,如inb_p、outb_p等。大部分体系都支持这些函数,尽管它们常常被扩展为与非暂停 I/O 同样的代码,因为如果体系使用一个合理的现代外设总线,没有必要额外暂停。
以下是ARM体系暂停式I/O宏的定义:
| #define outb_p(val,port) outb((val),(port)) #define outw_p(val,port) outw((val),(port)) #define outl_p(val,port) outl((val),(port)) #define inb_p(port) inb((port)) #define inw_p(port) inw((port)) #define inl_p(port) inl((port)) #define outsb_p(port,from,len) outsb(port,from,len) #define outsw_p(port,from,len) outsw(port,from,len) #define outsl_p(port,from,len) outsl(port,from,len) #define insb_p(port,to,len) insb(port,to,len) #define insw_p(port,to,len) insw(port,to,len) #define insl_p(port,to,len) insl(port,to,len) |
因为ARM使用内部总线,就没有必要额外暂停,所以暂停式的I/O函数被扩展为与非暂停式I/O同样的代码。
1.6、平台依赖性
由于自身的特性,I/O指令高度依赖于处理器,非常难以隐藏各体系间的不同。因此,大部分的关于端口 I/O的源码是平台依赖的。以下是x86和ARM所使用函数的总结:
IA-32 (x86)
x86_64
这个体系支持本章介绍的所有函数;port参数的类型为unsigned short。
ARM
端口映射到内存,并且支持本章介绍的所有函数;port参数的类型为unsigned int;字串函数用C语言实现。
2、使用 I/O 内存
尽管 I/O 端口在x86世界中非常流行,但是用来和设备通讯的主要机制是通过内存映射的寄存器和设备内存,两者都称为I/O 内存,因为寄存器和内存之间的区别对软件是透明的。
I/O 内存仅仅是一个类似于RAM 的区域,处理器通过总线访问该区域,以实现对设备的访问。同样,读写这个区域是有边际效应。
根据计算机体系和总线不同,I/O 内存可分为可以或者不可以通过页表来存取。若通过页表存取,内核必须先重新编排物理地址,使其对驱动程序可见,这就意味着在进行任何I/O操作之前,你必须调用ioremap;如果不需要页表,I/O内存区域就类似于I/O端口,你可以直接使用适当的I/O函数读写它们。
由于边际效应的缘故,不管是否需要 ioremap,都不鼓励直接使用I/O内存指针,而应使用专门的I/O内存操作函数。这些I/O内存操作函数不仅在所有平台上是安全,而且对直接使用指针操作 I/O 内存的情况进行了优化。
2.1、I/O 内存分配和映射
I/O 内存区在使用前必须先分配。分配内存区的函数接口在<linux/ioport.h>定义中:
| /* request_mem_region分配一个开始于start,len字节的I/O内存区。分配成功,返回一个非NULL指针;否则返回NULL。系统当前所有I/O内存分配信息都在/proc/iomem文件中列出,你分配失败时,可以看看该文件,看谁先占用了该内存区 */ struct resource *request_mem_region(unsigned long start, unsigned long len, char *name); /* release_mem_region用于释放不再需要的I/O内存区 */ void release_mem_region(unsigned long start, unsigned long len); /* check_mem_region用于检查I/O内存区的可用性。同样,该函数不安全,不推荐使用 */ int check_mem_region(unsigned long start, unsigned long len); |
在访问I/O内存之前,分配I/O内存并不是唯一要求的步骤,你还必须保证内核可存取该I/O内存。访问I/O内存并不只是简单解引用指针,在许多体系中,I/O 内存无法以这种方式直接存取。因此,还必须通过ioremap 函数设置一个映射。
| #include <asm/io.h>/* ioremap用于将I/O内存区映射到虚拟地址。参数phys_addr为要映射的I/O内存起始地址,参数size为要映射的I/O内存的大小,返回值为被映射到的虚拟地址 */ void *ioremap(unsigned long phys_addr, unsigned long size); /* ioremap_nocache为ioremap的无缓存版本。实际上,在大部分体系中,ioremap与ioremap_nocache的实现一样的,因为所有 I/O 内存都是在无缓存的内存地址空间中 */ void *ioremap_nocache(unsigned long phys_addr, unsigned long size); /* iounmap用于释放不再需要的映射 */ void iounmap(void * addr); |
经过 ioremap (和iounmap)之后,设备驱动就可以存取任何I/O内存地址。注意,ioremap返回的地址不可以直接解引用;相反,应当使用内核提供的访问函数。
2.2、访问I/O内存
访问I/O内存的正确方式是通过一系列专门用于实现此目的的函数:
| #include <asm/io.h>/* I/O内存读函数。参数addr应当是从ioremap获得的地址(可能包含一个整型偏移); 返回值是从给定I/O内存读取到的值 */ unsigned int ioread8(void *addr); unsigned int ioread16(void *addr); unsigned int ioread32(void *addr); /* I/O内存写函数。参数addr同I/O内存读函数,参数value为要写的值 */ void iowrite8(u8 value, void *addr); void iowrite16(u16 value, void *addr); void iowrite32(u32 value, void *addr); /* 以下这些函数读和写一系列值到一个给定的 I/O 内存地址,从给定的buf读或写count个值到给定的addr。参数count表示要读写的数据个数,而不是字节大小 */ void ioread8_rep(void *addr, void *buf, unsigned long count); void ioread16_rep(void *addr, void *buf, unsigned long count); void ioread32_rep(void *addr, void *buf, unsigned long count); void iowrite8_rep(void *addr, const void *buf, unsigned long count); void iowrite16_rep(void *addr, const void *buf, unsigned long count); void iowrite32_rep(void *addr,,onst void *buf,,nsigned long count); /* 需要操作一块I/O 地址时,使用下列函数(这些函数的行为类似于它们的C库类似函数): */ void memset_io(void *addr, u8 value, unsigned int count); void memcpy_fromio(void *dest, void *source, unsigned int count); void memcpy_toio(void *dest, void *source, unsigned int count); /* 旧的I/O内存读写函数,不推荐使用 */ unsigned readb(address); unsigned readw(address); unsigned readl(address); void writeb(unsigned value, address); void writew(unsigned value, address); void writel(unsigned value, address); |
2.3、像I/O 内存一样使用端口
一些硬件有一个有趣的特性: 有些版本使用 I/O 端口;而有些版本则使用 I/O 内存。不管是I/O 端口还是I/O 内存,处理器见到的设备寄存器都是相同的,只是访问方法不同。为了统一编程接口,使驱动程序易于编写,2.6内核提供了一个ioport_map函数:
| /* ioport_map重新映射count个I/O端口,使它们看起来I/O内存。此后,驱动程序可以在ioport_map返回的地址上使用ioread8和同类函数。这样,就可以在编程时,消除了I/O端口和I/O 内存的区别 */ void *ioport_map(unsigned long port, unsigned int count); /* ioport_unmap用于释放不再需要的映射 */ void ioport_unmap(void *addr); |
注意,I/O 端口在重新映射前必须使用request_region分配所需的I/O 端口。
3、ARM体系的I/O操作接口
s3c24x0处理器使用的是I/O内存,也就是说:s3c24x0处理器使用统一编址方式,I/O寄存器和内存使用的是单一地址空间,并且读写I/O寄存器和读写内存的指令是相同的。所以推荐使用I/O内存的相关指令和函数。但这并不表示I/O端口的指令在s3c24x0中不可用。如果你注意过s3c24x0关于I/O方面的内核源码,你就会发现:其实I/O端口的指令只是一个外壳,内部还是使用和I/O内存一样的代码。
下面是ARM体系原始的I/O操作函数。其实后面I/O端口和I/O内存操作函数,只是对这些函数进行再封装。从这里也可以看出为什么我们不推荐直接使用I/O端口和I/O内存地址指针,而是要求使用专门的I/O操作函数——专门的I/O操作函数会检查地址指针是否有效是否为IO地址(通过__iomem或__chk_io_ptr)
| #include <asm-arm/io.h> /* * Generic IO read/write. These perform native-endian accesses. Note * that some architectures will want to re-define __raw_{read,write}w. */ extern void __raw_writesb(void __iomem *addr, const void *data, int bytelen); extern void __raw_writesw(void __iomem *addr, const void *data, int wordlen); extern void __raw_writesl(void __iomem *addr, const void *data, int longlen); extern void __raw_readsb(const void __iomem *addr, void *data, int bytelen); extern void __raw_readsw(const void __iomem *addr, void *data, int wordlen); extern void __raw_readsl(const void __iomem *addr, void *data, int longlen); #define __raw_writeb(v,a) (__chk_io_ptr(a), *(volatile unsigned char __force *)(a) =(v)) #define __raw_writew(v,a) (__chk_io_ptr(a), *(volatile unsigned short __force *)(a) =(v)) #define __raw_writel(v,a) (__chk_io_ptr(a), *(volatile unsigned int __force *)(a) =(v)) #define __raw_readb(a) (__chk_io_ptr(a), *(volatile unsigned char __force *)(a)) #define __raw_readw(a) (__chk_io_ptr(a), *(volatile unsigned short __force *)(a)) #define __raw_readl(a) (__chk_io_ptr(a), *(volatile unsigned int __force *)(a)) |
关于__force和__iomem
| #include <linux/compiler.h> /* __force表示所定义的变量类型是可以做强制类型转换的 */ #define __force __attribute__((force)) /* __iomem是用来修饰一个变量的,这个变量必须是非解引用(no dereference)的,即这个变量地址必须是有效的,而且变量所在的地址空间必须是2,即设备地址映射空间。0表示normal space,即普通地址空间,对内核代码来说,当然就是内核空间地址了。1表示用户地址空间,2表示是设备地址映射空间 */ #define __iomem __attribute__((noderef, address_space(2))) |
I/O端口
| #include <asm-arm/io.h> #define outb(v,p) __raw_writeb(v,__io(p)) #define outw(v,p) __raw_writew((__force __u16) \ cpu_to_le16(v),__io(p)) #define outl(v,p) __raw_writel((__force __u32) \ cpu_to_le32(v),__io(p)) #define inb(p) ({ __u8 __v = __raw_readb(__io(p)); __v; }) #define inw(p) ({ __u16 __v = le16_to_cpu((__force __le16) \ __raw_readw(__io(p))); __v; }) #define inl(p) ({ __u32 __v = le32_to_cpu((__force __le32) \ __raw_readl(__io(p))); __v; }) #define outsb(p,d,l) __raw_writesb(__io(p),d,l) #define outsw(p,d,l) __raw_writesw(__io(p),d,l) #define outsl(p,d,l) __raw_writesl(__io(p),d,l) #define insb(p,d,l) __raw_readsb(__io(p),d,l) #define insw(p,d,l) __raw_readsw(__io(p),d,l) #define insl(p,d,l) __raw_readsl(__io(p),d,l) |
I/O内存
| #include <asm-arm/io.h> #define ioread8(p) ({ unsigned int __v = __raw_readb(p); __v; }) #define ioread16(p) ({ unsigned int __v = le16_to_cpu((__force __le16)__raw_readw(p));__v; }) #define ioread32(p) ({ unsigned int __v = le32_to_cpu((__force __le32)__raw_readl(p));__v; }) #define iowrite8(v,p) __raw_writeb(v, p) #define iowrite16(v,p) __raw_writew((__force __u16)cpu_to_le16(v), p) #define iowrite32(v,p) __raw_writel((__force __u32)cpu_to_le32(v), p) #define ioread8_rep(p,d,c) __raw_readsb(p,d,c) #define ioread16_rep(p,d,c) __raw_readsw(p,d,c) #define ioread32_rep(p,d,c) __raw_readsl(p,d,c) #define iowrite8_rep(p,s,c) __raw_writesb(p,s,c) #define iowrite16_rep(p,s,c) __raw_writesw(p,s,c) #define iowrite32_rep(p,s,c) __raw_writesl(p,s,c) |
注意:
1)、所有的读写指令(I/O操作函数)所赋的地址必须都是虚拟地址,你有两种选择:使用内核已经定义好的地址,如在include/asm-arm/arch-s3c2410/regs-xxx.h中定义了s3c2410处理器各外设寄存器地址(其他处理器芯片也可在类似路径找到内核定义好的外设寄存器的虚拟地址;另一种方法就是使用自己用ioremap映射的虚拟地址。绝对不能使用实际的物理地址,否则会因为内核无法处理地址而出现oops。
2)、在使用I/O指令时,可以不使用request_region和request_mem_region,而直接使用outb、ioread等指令。因为request的功能只是告诉内核端口被谁占用了,如再次request,内核会制止(资源busy)。但是不推荐这么做,这样的代码也不规范,可能会引起并发问题(很多时候我们都需要独占设备)。
3)、在使用I/O指令时,所赋的地址数据有时必须通过强制类型转换为 unsigned long,不然会有警告。
4)、在include\asm-arm\arch-s3c2410\hardware.h中定义了很多io口的操作函数,有需要可以在驱动中直接使用,很方便。
Linux系统对IO端口和IO内存的管理
http://blog.csdn.net/ce123/article/details/7204458
一、I/O端口
端口(port)是接口电路中能被CPU直接访问的寄存器的地址。几乎每一种外设都是通过读写设备上的寄存器来进行的。CPU通过这些地址即端口向接口电 路中的寄存器发送命令,读取状态和传送数据。外设寄存器也称为“I/O端口”,通常包括:控制寄存器、状态寄存器和数据寄存器三大类,而且一个外设的寄存 器通常被连续地编址。
二、IO内存
例如,在PC上可以插上一块图形卡,有2MB的存储空间,甚至可能还带有ROM,其中装有可执行代码。
三、IO端口和IO内存的区分及联系
这两者如何区分就涉及到硬件知识,X86体系中,具有两个地址空间:IO空间和内存空间,而RISC指令系统的CPU(如ARM、PowerPC等)通常只实现一个物理地址空间,即内存空间。内存空间:内存地址寻址范围,32位内存空间为2的32次幂,即4G。IO空间:X86特有的一个空间,与内存空间彼此独立的地址空间,32位X86有64K的IO空间。
IO端口:当寄存器或内存位于IO空间时,称为IO端口。一般寄存器也俗称I/O端口,或者说I/O ports,这个I/O端口可以被映射在Memory Space,也可以被映射在I/O Space。
IO内存:当寄存器或内存位于内存空间时,称为IO内存。
四、外设IO端口物理地址的编址方式
CPU对外设IO端口物理地址的编址方式有两种:一种是I/O映射方式(I/O-mapped),另一种是内存映射方式(Memory-mapped)。而具体采用哪一种则取决于CPU的体系结构。
1、统一编址
RISC指令系统的CPU(如,PowerPC、m68k、ARM等)通常只实现一个物理地址空间(RAM)。在这种情况下,外设I/O端口的物理地址 就被映射到CPU的单一物理地址空间中,而成为内存的一部分。此时,CPU可以象访问一个内存单元那样访问外设I/O端口,而不需要设立专门的外设I/O 指令。
统一编址也称为“I/O内存”方式,外设寄存器位于“内存空间”(很多外设有自己的内存、缓冲区,外设的寄存器和内存统称“I/O空间”)。
2、独立编址
而另外一些体系结构的CPU(典型地如X86)则为外设专门实现了一个单独地地址空间,称为“I/O地址空间”或者“I/O端口空间”。这是一个与CPU 地RAM物理地址空间不同的地址空间,所有外设的I/O端口均在这一空间中进行编址。CPU通过设立专门的I/O指令(如X86的IN和OUT指令)来访 问这一空间中的地址单元(也即I/O端口)。与RAM物理地址空间相比,I/O地址空间通常都比较小,如x86 CPU的I/O空间就只有64KB(0-0xffff)。这是“I/O映射方式”的一个主要缺点。
独立编址也称为“I/O端口”方式,外设寄存器位于“I/O(地址)空间”。
3、优缺点
独立编址主要优点是: 1)、I/O端口地址不占用存储器空间;使用专门的I/O指令对端口进行操作,I/O指令短,执行速度快。 2)、并且由于专门I/O指令与存储器访问指令有明显的区别,使程序中I/O操作和存储器操作层次清晰,程序的可读性强。 3)、同时,由于使用专门的I/O指令访问端口,并且I/O端口地址和存储器地址是分开的,故I/O端口地址和存储器地址可以重叠,而不会相互混淆。 4)、译码电路比较简单(因为I/0端口的地址空间一般较小,所用地址线也就较少)。 其缺点是:只能用专门的I/0指令,访问端口的方法不如访问存储器的方法多。
统一编址优点: 1)、由于对I/O设备的访问是使用访问存储器的指令,所以指令类型多,功能齐全,这不仅使访问I/O端口可实现输入/输出操作,而且还可对端口内容进行算术逻辑运算,移位等等; 2)、另外,能给端口有较大的编址空间,这对大型控制系统和数据通信系统是很有意义的。 这种方式的缺点是端口占用了存储器的地址空间,使存储器容量减小,另外指令长度比专门I/O指令要长,因而执行速度较慢。 究竟采用哪一种取决于系统的总体设计。在一个系统中也可以同时使用两种方式,前提是首先要支持I/O独立编址。Intel的x86微处理器都支持I/O 独立编址,因为它们的指令系统中都有I/O指令,并设置了可以区分I/O访问和存储器访问的控制信号引脚。而一些微处理器或单片机,为了减少引脚,从而减 少芯片占用面积,不支持I/O独立编址,只能采用存储器统一编址。
五、Linux下访问IO端口
对于某一既定的系统,它要么是独立编址、要么是统一编址,具体采用哪一种则取决于CPU的体系结构。 如,PowerPC、m68k等采用统一编址,而X86等则采用独立编址,存在IO空间的概念。目前,大多数嵌入式微控制器如ARM、PowerPC等并 不提供I/O空间,仅有内存空间,可直接用地址、指针访问。但对于Linux内核而言,它可能用于不同的CPU,所以它必须都要考虑这两种方式,于是它采 用一种新的方法,将基于I/O映射方式的或内存映射方式的I/O端口通称为“I/O区域”(I/O region),不论你采用哪种方式,都要先申请IO区域:request_resource(),结束时释放 它:release_resource()。
IO region是一种IO资源,因此它可以用resource结构类型来描述。
访问IO端口有2种途径:I/O映射方式(I/O-mapped)、内存映射方式(Memory-mapped)。前一种途径不映射到内存空间,直接使用 intb()/outb()之类的函数来读写IO端口;后一种MMIO是先把IO端口映射到IO内存(“内存空间”),再使用访问IO内存的函数来访问 IO端口。
1、I/O映射方式
直接使用IO端口操作函数:在设备打开或驱动模块被加载时申请IO端口区域,之后使用inb(),outb()等进行端口访问,最后在设备关闭或驱动被卸载时释放IO端口范围。
in、out、ins和outs汇编语言指令都可以访问I/O端口。内核中包含了以下辅助函数来简化这种访问:
inb( )、inw( )、inl( ) 分别从I/O端口读取1、2或4个连续字节。后缀“b”、“w”、“l”分别代表一个字节(8位)、一个字(16位)以及一个长整型(32位)。
inb_p( )、inw_p( )、inl_p( ) 分别从I/O端口读取1、2或4个连续字节,然后执行一条“哑元(dummy,即空指令)”指令使CPU暂停。
outb( )、outw( )、outl( ) 分别向一个I/O端口写入1、2或4个连续字节。
outb_p( )、outw_p( )、outl_p( ) 分别向一个I/O端口写入1、2或4个连续字节,然后执行一条“哑元”指令使CPU暂停。
insb( )、insw( )、insl( ) 分别从I/O端口读入以1、2或4个字节为一组的连续字节序列。字节序列的长度由该函数的参数给出。
outsb( )、outsw( )、outsl( ) 分别向I/O端口写入以1、2或4个字节为一组的连续字节序列。
流程如下:
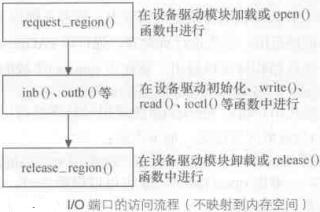
虽然访问I/O端口非常简单,但是检测哪些I/O端口已经分配给I/O设备可能就不这么简单了,对基于ISA总线的系统来说更是如此。通常,I/O设备驱 动程序为了探测硬件设备,需要盲目地向某一I/O端口写入数据;但是,如果其他硬件设备已经使用这个端口,那么系统就会崩溃。为了防止这种情况的发生,内 核必须使用“资源”来记录分配给每个硬件设备的I/O端口。资源表示某个实体的一部分,这部分被互斥地分配给设备驱动程序。在这里,资源表示I/O端口地 址的一个范围。每个资源对应的信息存放在resource中:
- struct resource {
- resource_size_t start;// 资源范围的开始
- resource_size_t end;// 资源范围的结束
- const char *name; //资源拥有者的名字
- unsigned long flags;// 各种标志
- struct resource *parent, *sibling, *child;// 指向资源树中父亲,兄弟和孩子的指针
- };
为什么使用树?例如,考虑一下IDE硬盘接口所使用的I/O端口地址-比如说从0xf000 到 0xf00f。那么,start字段为0xf000 且end 字段为0xf00f的这样一个资源包含在树中,控制器的常规名字存放在name字段中。但是,IDE设备驱动程序需要记住另外的信息,也就是IDE链主盘 使用0xf000 到0xf007的子范围,从盘使用0xf008 到0xf00f的子范围。为了做到这点,设备驱动程序把两个子范围对应的孩子插入到从0xf000 到0xf00f的整个范围对应的资源下。一般来说,树中的每个节点肯定相当于父节点对应范围的一个子范围。I/O端口资源树 (ioport_resource)的根节点跨越了整个I/O地址空间(从端口0到65535)。
任何设备驱动程序都可以使用下面三个函数,传递给它们的参数为资源树的根节点和要插入的新资源数据结构的地址:
request_resource( ) //把一个给定范围分配给一个I/O设备。
allocate_resource( ) //在资源树中寻找一个给定大小和排列方式的可用范围;若存在,将这个范围分配给一个I/O设备(主要由PCI设备驱动程序使用,可以使用任意的端口号和主板上的内存地址对其进行配置)。
release_resource( ) //释放以前分配给I/O设备的给定范围。
内 核也为以上函数定义了一些应用于I/O端口的快捷函数:request_region( )分配I/O端口的给定范围,release_region( )释放以前分配给I/O端口的范围。当前分配给I/O设备的所有I/O地址的树都可以从/proc/ioports文件中获得。
2、内存映射方式
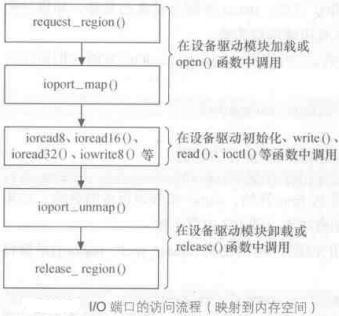
将IO端口映射为内存进行访问,在设备打开或驱动模块被加载时,申请IO端口区域并使用ioport_map()映射到内存,之后使用IO内存的函数进行端口访问,最后,在设备关闭或驱动模块被卸载时释放IO端口并释放映射。
映射函数的原型为: void *ioport_map(unsigned long port, unsigned int count); 通过这个函数,可以把port开始的count个连续的I/O端口重映射为一段“内存空间”。然后就可以在其返回的地址上像访问I/O内存一样访问这些I/O端口。但请注意,在进行映射前,还必须通过request_region( )分配I/O端口。
当不再需要这种映射时,需要调用下面的函数来撤消: void ioport_unmap(void *addr);
在设备的物理地址被映射到虚拟地址之后,尽管可以直接通过指针访问这些地址,但是宜使用Linux内核的如下一组函数来完成访问I/O内存:·读I/O内存 unsigned int ioread8(void *addr); unsigned int ioread16(void *addr); unsigned int ioread32(void *addr); 与上述函数对应的较早版本的函数为(这些函数在Linux 2.6中仍然被支持): unsigned readb(address); unsigned readw(address); unsigned readl(address); ·写I/O内存 void iowrite8(u8 value, void *addr); void iowrite16(u16 value, void *addr); void iowrite32(u32 value, void *addr); 与上述函数对应的较早版本的函数为(这些函数在Linux 2.6中仍然被支持): void writeb(unsigned value, address); void writew(unsigned value, address); void writel(unsigned value, address);
流程如下:
六、Linux下访问IO内存
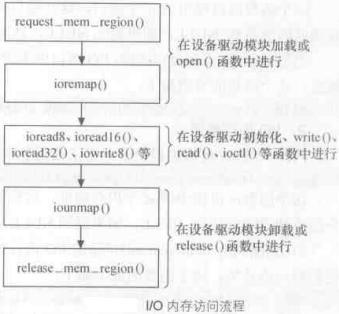
IO内存的访问方法是:首先调用request_mem_region()申请资源,接着将寄存器地址通过ioremap()映射到内核空间的虚拟地址, 之后就可以Linux设备访问编程接口访问这些寄存器了,访问完成后,使用ioremap()对申请的虚拟地址进行释放,并释放 release_mem_region()申请的IO内存资源。
struct resource *requset_mem_region(unsigned long start, unsigned long len,char *name); 这个函数从内核申请len个内存地址(在3G~4G之间的虚地址),而这里的start为I/O物理地址,name为设备的名称。注意,。如果分配成功,则返回非NULL,否则,返回NULL。 另外,可以通过/proc/iomem查看系统给各种设备的内存范围。
要释放所申请的I/O内存,应当使用release_mem_region()函数: void release_mem_region(unsigned long start, unsigned long len)
申请一组I/O内存后, 调用ioremap()函数: void * ioremap(unsigned long phys_addr, unsigned long size, unsigned long flags); 其中三个参数的含义为: phys_addr:与requset_mem_region函数中参数start相同的I/O物理地址; size:要映射的空间的大小; flags:要映射的IO空间的和权限有关的标志;
功能:将一个I/O地址空间映射到内核的虚拟地址空间上(通过release_mem_region()申请到的)
流程如下:
六、ioremap和ioport_map
下面具体看一下ioport_map和ioport_umap的源码:
- void __iomem *ioport_map(unsigned long port, unsigned int nr)
- {
- if (port > PIO_MASK)
- return NULL;
- return (void __iomem *) (unsigned long) (port + PIO_OFFSET);
- }
- void ioport_unmap(void __iomem *addr)
- {
- /* Nothing to do */
- }
ioport_map仅仅是将port加上PIO_OFFSET(64k),而ioport_unmap则什么都不做。这样portio的64k空间就被映射到虚拟地址的64k~128k之间,而ioremap返回的虚拟地址则肯定在3G之上。ioport_map函数的目的是试图提供与ioremap一致的虚拟地址空间。分析ioport_map()的源代码可发现,所谓的映射到内存空间行为实际上是给开发人员制造的一个“假象”,并没有映射到内核虚拟地址,仅仅是为了让工程师可使用统一的I/O内存访问接口ioread8/iowrite8(......)访问I/O端口。 最后来看一下ioread8的源码,其实现也就是对虚拟地址进行了判断,以区分IO端口和IO内存,然后分别使用inb/outb和readb/writeb来读写。
- unsigned int fastcall ioread8(void __iomem *addr)
- {
- IO_COND(addr, return inb(port), return readb(addr));
- }
- #define VERIFY_PIO(port) BUG_ON((port & ~PIO_MASK) != PIO_OFFSET)
- #define IO_COND(addr, is_pio, is_mmio) do { \
- unsigned long port = (unsigned long __force)addr; \
- if (port < PIO_RESERVED) { \
- VERIFY_PIO(port); \
- port &= PIO_MASK; \
- is_pio; \
- } else { \
- is_mmio; \
- } \
- } while (0)
- 展开:
- unsigned int fastcall ioread8(void __iomem *addr)
- {
- unsigned long port = (unsigned long __force)addr;
- if( port < 0x40000UL ) {
- BUG_ON( (port & ~PIO_MASK) != PIO_OFFSET );
- port &= PIO_MASK;
- return inb(port);
- }else{
- return readb(addr);
- }
- }
七、总结
外 设IO寄存器地址独立编址的CPU,这时应该称外设IO寄存器为IO端口,访问IO寄存器可通过ioport_map将其映射到虚拟地址空间,但实际上这 是给开发人员制造的一个“假象”,并没有映射到内核虚拟地址,仅仅是为了可以使用和IO内存一样的接口访问IO寄存器;也可以直接使用in/out指令访 问IO寄存器。
例如:Intel x86平台普通使用了名为内存映射(MMIO)的技术,该技术是PCI规范的一部分,IO设备端口被映射到内存空间,映射后,CPU访问IO端口就如同访 问内存一样。
外设IO寄存器地址统一编址的CPU,这时应该称外设IO寄存器为IO内存,访问IO寄存器可通过ioremap将其映射到虚拟地址空间,然后再使用read/write接口访问。